I have had a good time getting familiar with Python and web scraping. Python has been on my mind for the last couple of years. Why would you want to write code in Python?
- Well, it is cross-platform for one - so your code will function the same in Mac, PC, or Linux computers.
- the code is overall simple (typically less code than other languages)
- Supports complex scenarios such as Object-Oriented Programming, Machine Learning/AI, and Web/App Development
- Lots of really good external packages to help in your code development
My favorite way to learn programming languages is to apply it to application projects. This is my first project I am sharing with the community. I am excited to take you through this tutorial and teach you how to use some basic syntax to fully web scrap a website you are interested in.
Simple Web App
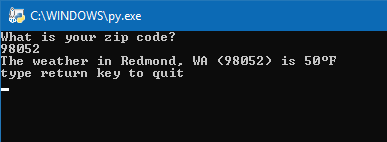
The goal of the project is to create a python application that scans the content of Weather.com delivering the weather temperature without browsing to the website. Most of the content was learned by going through chapters 1-11 in the Automate the Boring Stuff website. (I am so glad I finished chapter 11 before starting this project, below states why)
RegEx or not
When I thought of scraping content from a website - my first thought was there would have to be some sort of library to deliver a request/response of the page. I would parse the source code of the page using some sort of fancy regular expression. If you haven’t worked with regular expression before it is a clever way to pick a sequence of characters that can either search or find/replace content in a given input of plain text typically code markup. I think if I would have used this method I could have easily spend about a day and a half working on the perfect regular expression and validation (note: here is a good place to prototype RegEx - https://www.regexpal.com/)
Good news is I didn’t need to use regular expression at all (well full disclosure I did use it for input validation - but that was the easy part). There is a good python library called BeautifulSoup that really makes python web scraping easy as pie! I’ll show you how to use it below. But first let’s setup your IDE
IDE Setup
For most of my coding I use VSCode as it is a good cross platform IDE. However for Python I really enjoy using PyCharm instead. PyCharm has a couple of features that VSCode has yet to implement including:
- vEnv (virtual environments) that allow you install certain libraries just for your project (isolation from your developer machine)
- Great debugger and integrated Python console
- Overall designed for Python and many delightful some features
Download/Install PyCharm and the latest/greatest python 3.7.3 was available as of when I wrote this article.
- Open PyCharm -> Create new Project -> call it SimpleWeatherApp
- Add a link to the python interpreter you just downloaded in PyCharm -> Settings- >Project: SimpleWeatherApp -> Project Interpreter
- Right-Click SimpleWeatherApp and click New -> Python File
- Name pyWeather.py
Add some comments at the top of your project to identify the author and created date. Something simple for now.
'''
pyWeather.py Created by Nate Bruneau @natebruneau Created date: 2019.04.20
'''
Import some required libraries
- In PyCharm -> File -> Settings -> Project:SimpleWeatherApp -> click +
- Search beautifulsoup4 -> select install package
- Search requests -> select install package
Current Package List should look something like below
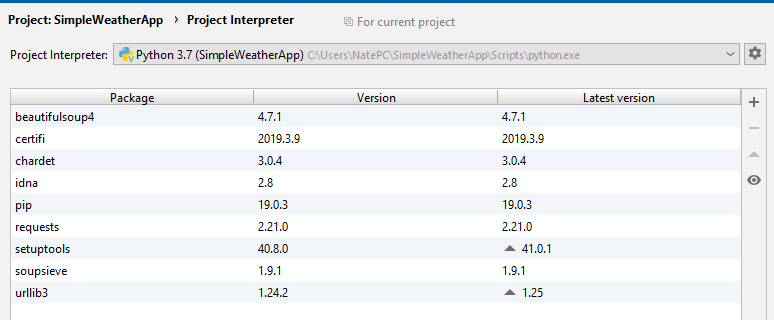
Add lines to your PyWeather.py
import requests import bs4 import re
Go ahead and right-click PyWeather.py and click Run ‘pyWeather’ - at this point nothing should output besides “Process finished with exit code 0”
What… I thought you said no RegEx
Okay - so no RegEx for web scraping but we need some to validate the zip code of the user’s input. Here is the next block of code.
while True:
print("What is your zip code?")
zipCode = input()
#build regex parser for zipcode
zipcodeRegEx = re.compile(r'^\d{5}$')
mo = zipcodeRegEx.search(zipCode)
if mo == None:
print("Hmm.. I don't recognize " + zipCode + " as a proper zipcode. Use digit like 98052")
continue
break
To quickly explain the code above, I’ll try to break this up :
- The while true loop will continue iterating forever or until a break condition is captured. If a continue statement is initiated then the current run-time code will bounce back to the top of the loop.
- print(“What is your zip code?”) asks the user a question while zipCode = input() captures the input
- RegEx parser is set to analyze the input and has a sequence of characters ^d{5}$ to be able to filter the text for the zip code. The carrot means this is the start of the pattern, the d{5} means any 5 digits and the $ means end of the pattern. (note: to remember carrot goes first and $ goes last I find the phrase - carrots cost money that I learned from the automate the boring stuff blog.) I highly encourage you to learn more about regular expressions and read chapter 7 of automate the boring stuff to get a good overview.
- the If statement analyzes if there were no searches found (ie. input was not a 5 digit zip code) then print a message and continue to the beginning of loop
Web Request
The next block of code will get the weather page I am looking for (weather by zip code) and deliver a response res. If the request fails with any exception the try/except will catch an exception and display the issue.
res = requests.get('https://weather.com/weather/today/l/' + zipCode + ':4:US') try: res.raise\_for\_status() except Exception as exc: print('There was a problem: %s' % (exc))
Soup Magic
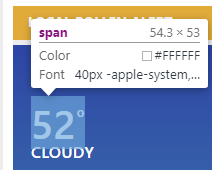
This next part really showcases what this Beautiful Soup package can do. What you want to do now is open your web browser and open the web debugger (likely press F12). In my example I will use chrome. Open the weather.com website then click the inspector button. After scroll over to the current temperature with the inspector. Then view the corresponding code on the right. The code below searches for the div class called today_nowcard-temp that we found during our web inspector session. The mydivs[0].getText() code returns the value that corresponds to that web element.
Click on the inspector button

Hover with your mouse(inspector) over the current temp
check the corresponding code over on the right hand pane
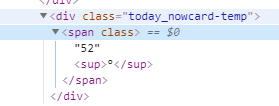
Code below:
weatherSoup = bs4.BeautifulSoup(res.text,features="html.parser") mydivs = weatherSoup.findAll("div", {"class": "today\_nowcard-temp"}) weather = mydivs[0].getText()
Now this is a bit of extra credit - but I also want to show the location, so use the same method above to find the location (here is the code below for that you can validate against)
locationdiv = weatherSoup.findAll("h1", {"class": "today\_nowcard-location"}) location = locationdiv[0].getText()
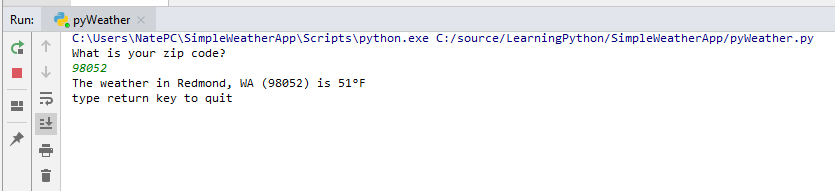
For the finale - the code below prints the variables we used BeautifulSoup to web scrape and then returns to the user
print('The weather in ' + location + ' is ' + weather + 'F') print('type return key to quit') input() # to pause
Final Thoughts
Couple things to note: Now if you want to take this python application and run it on your computer - you will have to load the modules that you previously loaded in your vEnv. Here are the commands to do this:
pip install requests pip install bs4
Congratulations - you created your first of python application with web scraping ability. Let me know what you think of the tutorial. Also when you are writing code like this be sure to think about unit testing around some of your input validation and conditions. For this scenario you could think about the following conditions for unit testing:
- input numbers over 5 digits
- what happens when your internet connection is down?
- negative number
- non-number inputs
Thanks again and I hope you enjoy coding with python. Here is a link to the complete code on my github page.